Mi IA local se optimizó a sí misma: la arquitectura que nació de darle las llaves al modelo
PorAdrián Campos Garrido
el
Llevaba un tiempo con Ollama en el homelab, probando, aprendiendo, haciendo que las cosas funcionaran. Monté mi primer despliegue, estudié cómo encajaban las piezas y empecé a sentir que podía ir un paso más allá. Pero llegó un momento en el que me planté una pregunta incómoda: ¿esto escalaría si más de una persona lo usaba a la vez? La respuesta honesta era no. Tras investigar a fondo las alternativas, quedé claro que las herramientas que estaba usando no eran las más adecuadas para ese propósito. Y en lugar de seguir parcheando, decidí replantearlo todo desde cero.
La primera decisión fue el cambio más importante: adiós Ollama, hola vLLM. No es que Ollama sea malo —es fantástico para desarrollo y prototipos— pero cuando el objetivo es ofrecer servicios a múltiples usuarios concurrentes, vLLM es otra liga. Su motor de inferencia y su gestión de la memoria están pensados para soportar peticiones simultáneas en tiempo real, que es justo lo que necesitaba.
El primer despliegue con vLLM funcionó. Pero no rápido. Me topé con un TTFB (Time To First Byte) que no me convencía. Es decir, el tiempo que pasaba desde que lanzaba una petición al modelo hasta que recibía la primera respuesta era demasiado alto. Parte del problema venía de un cambio de modelo que hice en paralelo: pasé de modelos menos exigentes como un Gemma 3 (27B) o un Mistral (19B) a un Qwen 3.6 (27B), con más capacidades pero también con un peso mucho mayor. Fue ese salto el que empezó a darme los primeros problemas de rendimiento.
Tenía un despliegue funcional, pero más lento de lo que me gustaría. Y entonces se me ocurrió algo que al principio sonó absurdo: aún siendo lento, ¿por qué no aprovechar el propio modelo para que me ayudara a mejorarlo?
Antes de llegar a ese punto, ya me había metido a investigar por mi cuenta las opciones de configuración de vLLM. Hay muchísimas, y poco a poco fui entendiendo cuáles podrían servir para optimizar el despliegue. Pero al final, el acierto fue pasarle al modelo la combinación perfecta: por un lado, la configuración del despliegue que tenía, y por otro, el log que vLLM genera al levantarse. Por suerte, ese log es muy claro y permite ver de un vistazo la memoria VRAM disponible para el KV Cache, la memoria que se usa para calcular los Cuda Graphs, y qué opciones elige vLLM por defecto al cargar ese modelo en concreto.
El resultado fue excelente. El modelo no solo me sugirió qué parámetros podrían venirme bien, sino que me dio los valores concretos que debía usar en función de lo que quisiera priorizar: ¿prefería dar soporte a más usuarios concurrentes o ampliar el contexto de cada conversación? Me lo desglosó y me explicó los parámetros para cada escenario.
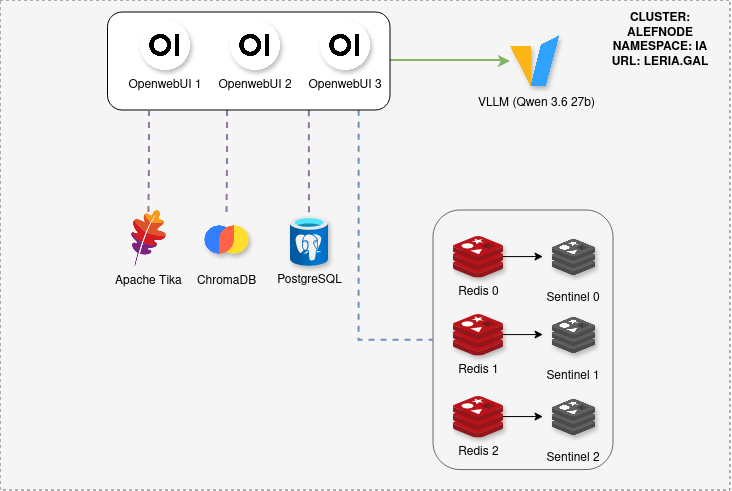
Pero no se quedó ahí. Al pasarle también el YAML completo de despliegue que estaba usando sobre K3S, entendió perfectamente la infraestructura: dos GPUs de 16 GB de VRAM cada una, sin enlace NVLink entre ellas, por lo que toda la comunicación viajaba por PCIe, que es un cuello de botella notable. A partir de ahí me propuso optimizaciones específicas para esa limitación hardware, como ampliar la memoria compartida (SHM) del Pod para que la comunicación entre GPUs fuera más fluida. Al final del artículo dejo el YAML que uso actualmente por si queréis echarle un vistazo. Aunque como resumen las opciones que uso actualmente son:
Las mejoras, sin embargo, no terminan con vLLM. Añadí dos capas adicionales a la arquitectura para cubrir dos necesidades que me quedaban sin resolver.
La primera es un servicio de embedding dedicado, para mejorar la comprensión del modelo a la hora de analizar frases y contextos largos. Tras revisar los embeddings disponibles con mayores capacidades y contextos, me decanté por el qwen3-embedding (8B), que desplegé en otro worker del cluster con su propia GPU. No hay mucho que contar sobre esta parte: simplemente funciona de forma muy eficiente y la diferencia en la calidad de los resultados se nota desde el primer momento.
La segunda capa es un servicio de análisis de PDF, para que los documentos se procesen y limpien antes de enviarlos al modelo. Elegí Apache Tika, desplegado también sobre el cluster con varias réplicas para ganar velocidad en caso de subidas concurrentes. De este componente solo echo de menos que no disponga de OCR integrado para el análisis de imágenes y su transformación a texto. Es algo que tengo pendiente de investigar; de hecho, ya he probado el propio modelo para esta tarea y funciona bastante bien, así que puede que la solución esté más cerca de lo que pienso.
A continuación, el YAML de despliegue que estoy utilizando. Un apunte: el bloqueo de red se hace de esta forma porque hasta que pueda redesplegar el cluster completo no puedo cambiar el plugin de red de K3S: